
Nvidia Vera Rubin徹底解説
目次
はじめに
皆さんは、AI技術がどのような仕組みで動いているかご存じでしょうか。ChatGPTのような対話型AIや画像生成AIなど、私たちが日常的に使うサービスの裏側には、膨大な計算能力を持つコンピュータシステムが存在しています。
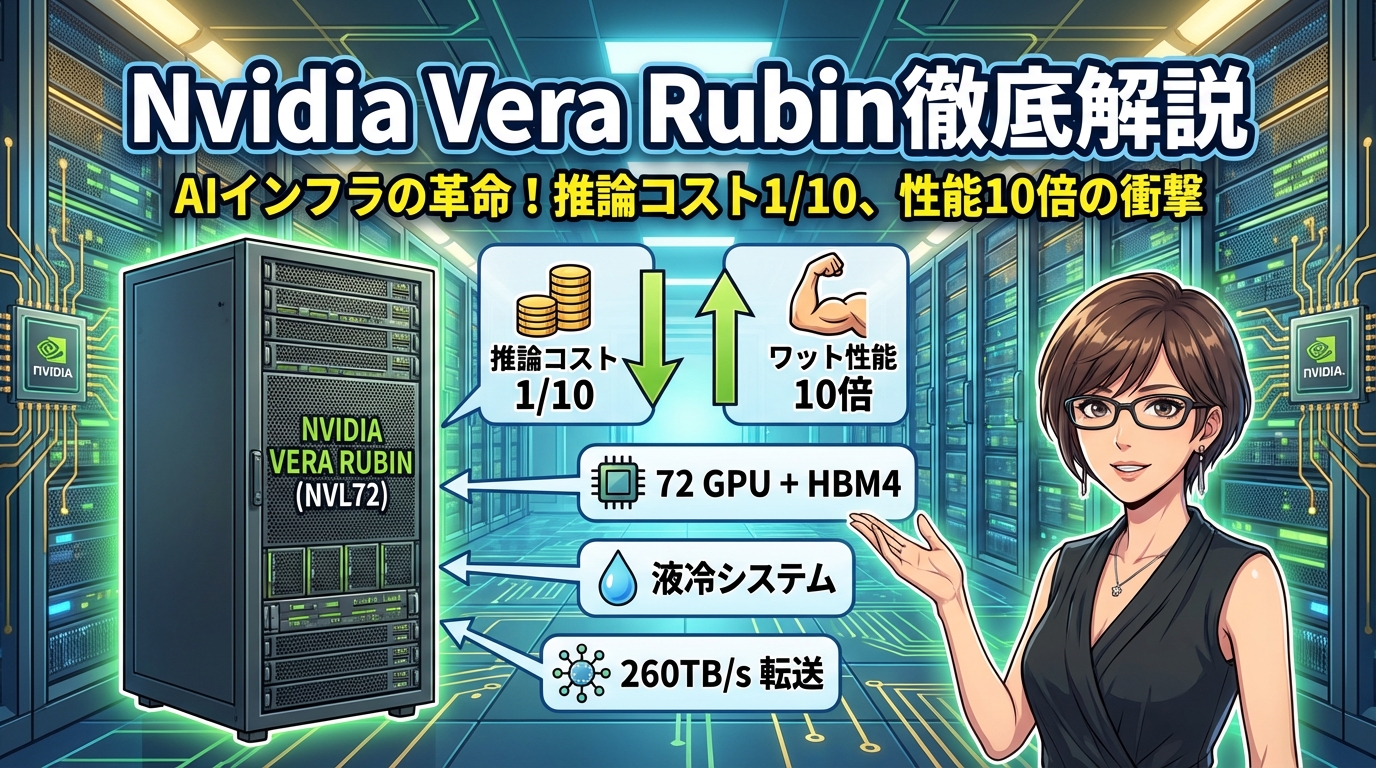
2026年2月、AI向け半導体で世界をリードするNvidia(エヌビディア)が、次世代のAIインフラシステム「Vera Rubin(ベラ・ルービン)」の量産体制に入ったことが明らかになりました。この新システムは、現行製品と比べて 「推論トークンコスト」 を最大10分の1に削減し、「ワットあたり性能」 を10倍向上させるという、驚異的な効率性を実現するとされています。
この記事では、Vera Rubinがどのような技術なのか、これまでの製品からどう進化したのか、そしてAI業界全体にどのような影響を与えるのかについて、できるだけわかりやすく解説していきます。難しい専門用語もできる限り噛み砕いて説明しますので、ぜひ最後までお付き合いください。
Nvidia Vera Rubinとは?次世代AIインフラの全貌
ラックスケールシステムという概念
まず、「Vera Rubin」とは何なのかを理解するために、少し前提知識をお話しします。
通常、私たちがパソコンと呼ぶものは、机の上に置けるサイズのコンピュータです。しかし、AIの学習や推論(質問に答えること)には、個人のパソコンとは比較にならないほど巨大な計算能力が必要になります。そのため、データセンターと呼ばれる施設に、冷蔵庫ほどの大きさの「ラック」と呼ばれる棚のような装置を何百台も並べて、そこに高性能なコンピュータ部品を詰め込むのです。
Vera Rubinは、この「1つのラック」に72個ものGPU(画像処理や並列計算に特化した半導体チップ)を搭載した、いわば 「ラック丸ごと1台のスーパーコンピュータ」 です。Nvidiaではこれを 「NVL72システム」 と呼んでいます。
圧倒的な性能向上の秘密
Vera Rubinの最大の特徴は、その効率性にあります。具体的には以下のような性能を実現します。
- 推論トークンコストが10分の1に削減:AIが質問に答えるとき、「トークン」という単位で文章を処理します。この1トークンを処理するためのコストが、従来の10分の1になるということです
- ワットあたり性能が10倍向上:同じ電力で10倍の計算ができる、または同じ計算を10分の1の電力で実行できるということです
- ラック全体のデータ転送速度が260TB/s:これは1秒間に260テラバイト(映画約5万本分)のデータを処理できる速度です
この性能向上は、データセンターを運営する企業にとって非常に重要です。なぜなら、AIサービスの運用コストの大部分は 「電気代」 だからです。同じサービスを提供するのに必要な電力が10分の1になれば、利益が大きく改善されるというわけですね。
130万個の部品で構成される精密機械
Vera Rubin 1ラックには、なんと約130万個もの部品が使われています。これは前世代のBlackwell(ブラックウェル)システムの約120万個から、さらに10万個も増加した数字です。
主な構成要素は以下の通りです。
- Rubin GPU(72個):計算の中心となる高性能プロセッサ
- Vera CPU(88コアArmプロセッサ):制御や補助計算を担当
- HBM4メモリ:各GPUに搭載される超高速メモリ
- NVLink 6スイッチ:72個のGPU同士を超高速でつなぐ配線網
- 液冷システム:220kW(一般家庭の約200軒分)の熱を冷やす冷却装置
- 電源システム:安定した電力供給のための装置
- 銅ケーブル:1ラックあたり5,000本以上の配線
これらが一体となって動作することで、初めてVera Rubinの性能が実現されるのです。
6つの新開発チップによる革新
Vera Rubinでは、以下の6つのチップがすべて新設計されています。
1. Vera CPU(88コアArmv9.2)
前世代のGrace CPUと比べて、ワットあたりの性能が2倍に向上しています。CPUはコンピュータの「司令塔」のような役割を果たす部品です。
2. Rubin GPU
50ペタフロップス(1秒間に5京回の計算)という驚異的な演算性能を持ちます。Blackwell GPUと比べて2.5倍の性能です。さらに、第3世代の 「Transformer Engine」 という、AI計算に特化した機能が搭載されており、データを圧縮しながら高速処理できるようになっています。
3. NVLink 6スイッチ
72個のGPUを相互に接続する「高速道路網」のような役割を果たします。1つの接続あたり3.6TB/s(前世代の2倍)という、途方もない速度でデータをやり取りできます。
4. ConnectX-9 SuperNIC(800Gb/s)
ラックの外部ネットワークとの接続を担当する、いわば「玄関口」です。800ギガビット毎秒という超高速通信が可能です。
5. BlueField-4 DPU
「DPU」 とはData Processing Unitの略で、セキュリティ処理やデータ保存などの作業をGPUの代わりに実行することで、GPUをAI計算に専念させる役割を持ちます。
6. Spectrum-6イーサネットスイッチ / Quantum-X800 InfiniBand
ラックとラックの間を接続するための、データセンター内のネットワーク機器です。これも800Gb/sの超高速通信に対応しています。
このように、チップセット全体が一から再設計されていることが、Vera Rubinの圧倒的な性能向上の理由なのです。
Blackwellからの進化:何が変わったのか
前世代Blackwellの成功
Vera Rubinを理解するには、その前の世代である 「Blackwell」 について知っておく必要があります。
Blackwellは2024年に発表されたNvidiaのAIシステムで、当時としては画期的な性能を持っていました。Microsoft、Google、Amazon、Meta(旧Facebook)、Oracleなど、世界中の大手テック企業が採用し、現在も週に数千ラック単位で量産・出荷されています。しかも、生産される製品はすべて予約で埋まっているという、まさに「引く手あまた」の状態です。
Blackwellの成功により、Nvidiaの株価は発表以降、100%以上も上昇しました。それほどまでに、AI業界ではNvidiaの技術が必要とされているのです。
性能とコストの比較
では、BlackwellからVera Rubinへは、具体的にどう進化したのでしょうか。主な違いを見ていきましょう。
消費電力と性能のバランス
Blackwellの1ラックあたりの消費電力は約120kWでしたが、Vera Rubinは約220kWと、約2倍になっています。「電力が2倍になったら、電気代も2倍で効率悪いのでは?」と思われるかもしれません。
しかし重要なのは、消費電力は2倍になったものの、 出力される計算性能は10倍以上 になっているという点です。つまり、電力1ワットあたりの「仕事量」が5倍に向上しているということになります。
トークン生成コストの劇的削減
AIサービス事業者にとって最も重要な指標の一つが、「1トークンあたりのコスト」です。トークンとは、AIが文章を処理する際の最小単位のようなもので、例えば「こんにちは」という言葉は複数のトークンに分割されて処理されます。
Vera Rubinでは、このトークン生成コストが Blackwellの10分の1 になります。これは、同じAIサービスを提供するのに必要なコストが大幅に下がることを意味します。
データ転送速度の向上
AI計算では、大量のデータを高速にやり取りする必要があります。Vera RubinのNVLink 6は、1つのGPUあたり3.6TB/sのデータ転送速度を実現しており、これはBlackwellの1.8TB/sの2倍です。
ラック全体では260TB/sという、信じられないような速度でデータが飛び交います。これにより、72個のGPUがまるで1つの巨大な脳のように協調して動作できるのです。
「買い控え不要」という戦略
新製品が発表されると、「今買うと損するかも」と思って購入を控える人が出てきます。これを 「買い控え」 と言います。
しかし、Nvidia CEOのJensen Huang(ジェンセン・フアン)氏は、インタビューの中で興味深い発言をしています。
「顧客には『より少なく買ってほしい』と伝える珍しいCEOだ。毎年の新世代に合わせて購入してほしい。BlackwellとRubinを並べて異なるワークロードに使うことを想定している」
つまり、BlackwellとVera Rubinは 「共存」 するように設計されているということです。古いシステムが無駄になるのではなく、それぞれが得意な処理を担当するという考え方です。
これにより、顧客は「今買っても損しない」と安心して購入でき、Nvidiaとしては継続的に製品を販売できるという、双方にメリットのある戦略になっています。
ラック1台の価格とその価値
Vera Rubin 1ラックの価格は、推定で375万~400万ドル(日本円で約5億6,000万~6億円)と見られています。これはBlackwellの300万~320万ドルと比べて、20~25%ほど高い価格です。
「高くなったら買ってもらえないのでは?」と思われるかもしれませんが、重要なのは 「投資対効果」 です。
価格が25%高くなっても、トークンあたりのコストが10分の1になるなら、長期的には大幅にコストが削減されます。業界関係者の試算では、投資を回収するまでの期間が、Blackwellの18~24ヶ月から、Vera Rubinでは12~18ヶ月に短縮されると見られています。
つまり、初期費用は高くても、「元が取れる」までの時間が短いため、企業としては導入する価値が高いということですね。
グローバルサプライチェーン:世界中から集まる部品
80社以上、20ヶ国以上にまたがる供給網
Vera Rubin 1ラックを製造するには、世界中から部品を調達する必要があります。その規模は想像を超えるものです。
- サプライヤー数:80社以上
- 製造拠点:20ヶ国以上、約350工場
- 部品点数:約130万個
これほど複雑なサプライチェーン(供給網)を管理することは、非常に高度な技術と経験が必要です。逆に言えば、この複雑さこそが、競合他社が簡単に真似できない 「参入障壁」 となっているのです。
主要サプライヤーと役割分担
Vera Rubinを構成する主要な部品と、それを製造する企業を見ていきましょう。
チップ製造
Rubin GPU、Vera CPU、NVLinkスイッチなどの半導体チップは、すべて TSMC(Taiwan Semiconductor Manufacturing Company) という台湾の企業が製造しています。TSMCは世界最先端の半導体製造技術を持つ企業で、AppleのiPhoneに使われるチップなども製造しています。
HBM4メモリ
GPUには 「HBM(High Bandwidth Memory)」 という特殊な高速メモリが搭載されます。Vera Rubinでは最新世代の 「HBM4」 が使われており、これを製造できるのは世界でもSK Hynix(韓国)、Samsung(韓国)、Micron(アメリカ)の3社しかありません。
各GPUの上下に8スタックずつ、合計16スタックのHBM4が搭載されるため、1ラックには膨大な量のメモリが必要になります。現在、このHBM4の供給が需要に追いついておらず、業界全体で争奪戦が起きているとも言われています。
ラック組立
シャーシ(骨組み)やフレームなどの機構部品は、Foxconn(台湾)やInterplex(シンガポール)などの企業が製造しています。Foxconnは、iPhoneの組み立てでも有名な世界最大級の電子機器受託製造企業です。
液冷システム
220kWもの電力を消費するVera Rubinは、膨大な熱を発生させます。この熱を効率的に冷やすために、液体冷却システムが採用されています。
液冷システムの主要部品は、Delta Electronics(台湾)、Vertiv(アメリカ)、Ouru(台湾)、Boyd(アメリカ)、Cooler Master(台湾)などの企業が製造しています。コールドプレート(チップに直接触れる冷却板)、マニホールド(冷却液の分配装置)、冷却ノズルなど、精密な部品が組み合わされています。
電源システム
安定した電力供給のために、MegMeet(中国)、Liteon(台湾)、Flex(シンガポール)などの企業が電源装置を提供しています。さらに、電圧を細かく制御するためのチップは、Infineon(ドイツ)、Analog Devices(アメリカ)、STMicroelectronics(スイス)などが製造しています。
ケーブルと接続部品
1ラックあたり5,000本以上の銅ケーブルが使われており、これらはAmphenol(アメリカ)、Bizlink(台湾)などが供給しています。また、バスバー(太い電流を流すための金属板)なども必要です。
その他の機構部品
配管、ホース接続部などの細かい部品は、PINDA、JPC、Rico Dealなど、多数の専門メーカーが提供しています。
HBM4メモリ不足への対応
先ほども触れましたが、HBM4メモリは現在、供給が非常に逼迫しています。これは、AI需要の急拡大により、すべてのGPUメーカーがHBM4を求めているためです。
NvidiaのCFO(最高財務責任者)であるColette Kress氏は、インタビューの中で次のように述べています。
「サプライチェーン全体に詳細な予測を共有し、出荷スケジュールと供給を綿密に調整している。良好な状態だ」
つまり、Nvidiaは早い段階からサプライヤーと密接に連携し、必要な量を確保する体制を整えているということです。過去にBlackwellの初期モデルで過熱問題が発生した経験から、供給面でのリスク管理を徹底しているようですね。
とはいえ、HBM4の供給不足は2026年後半の出荷ペースに影響を与える可能性があるため、今後の動向が注目されています。
製造拠点の分散とリスク管理
グローバルなサプライチェーンには、地政学的なリスクもあります。例えば、米中間の貿易摩擦や関税問題、台湾海峡の緊張などです。
Nvidiaはこうしたリスクに対応するため、製造拠点の分散を進めています。
米国内製造の拡大
TSMCは現在、アリゾナ州に最先端の半導体工場を建設中で、すでにBlackwellの一部はこの工場で製造されています。Vera Rubinも将来的には米国内で製造される可能性があります。
Nvidiaは、2029年までに最大5,000億ドル(約75兆円)相当のAIインフラを米国で製造するという目標を表明しています。
メキシコでの組立
Foxconnはメキシコに新工場を建設し、ラック組立を行う計画です。これにより、北米市場への供給がスムーズになります。
このように、供給網を複数の国・地域に分散させることで、特定の地域でのトラブルが全体に影響しにくくなるよう工夫されているのです。
競合製品との比較:AMD Heliosとの違い
AMD Heliosの概要
Nvidiaの独走状態が続くAI半導体市場ですが、競合他社も黙っているわけではありません。
AMD(Advanced Micro Devices) は、2026年後半に 「Helios」 というラックスケールAIシステムを発表する予定です。これはAMDとして初めての、ラック丸ごと1台のシステムであり、Vera Rubinの直接の競合製品となります。
AMD幹部は、インタビューの中で次のように述べています。
「顧客は容量だけでなく、Nvidiaへの価格牽制のためにも実用的な第2の選択肢を求めている」
つまり、企業はNvidia一社に依存することのリスクを感じており、代替品を求めているということです。これは自然な動きと言えるでしょう。
技術的な違いと優位性
では、Nvidia Vera RubinとAMD Heliosを比較すると、どのような違いがあるのでしょうか。
ソフトウェアエコシステムの差
Nvidiaの最大の強みは、「CUDA(クーダ)」 という開発環境にあります。CUDAは、NvidiaのGPUでプログラムを動かすためのツールキットで、世界中の研究者や開発者がこれを使ってAIアプリケーションを作っています。
過去15年以上にわたってCUDAが業界標準となっているため、新しいAIモデルを開発する際も、まずNvidia GPUで動くことを前提に設計されることが多いのです。
一方、AMDは 「ROCm」 という開発環境を提供していますが、CUDAと比べるとまだ成熟度で劣ります。既存のCUDAベースのコードをROCmに移植するには、それなりの手間がかかるため、「わざわざAMDに乗り換える理由がない」と考える企業も多いのです。
ラックスケールシステムの経験値
Nvidiaは、Hopper、Blackwellと、すでに複数世代のラックスケールシステムを開発・出荷してきた実績があります。その過程で、冷却、電源、配線、信頼性など、さまざまな課題を解決してきました。
一方、AMDにとってHeliosは初めてのラックスケールシステムです。Nvidia幹部は次のように述べています。
「このスケールのシステムを設計する複雑さを理解するには多くの成長痛が伴う。我々が唯一できる企業とは言わないが、多くの困難を経験した」
つまり、ラックスケールシステムの開発には、単にチップの性能を上げるだけでなく、システム全体の統合技術が必要であり、それには経験が不可欠だということです。
価格競争力
AMDの強みは、価格競争力にあります。一般的に、AMD製品はNvidia製品よりも10~20%程度安価に設定されることが多いです。
予算に制約がある企業や、「Nvidiaほどの性能は必要ないが、ある程度のAI計算能力は欲しい」という企業にとって、AMDは魅力的な選択肢となるでしょう。
自社チップ開発の動き
実は、Nvidiaの大口顧客である大手テック企業の多くが、自社でAI専用チップを開発しています。
- Google TPU v6:Googleが独自開発したAI専用チップ
- AWS Trainium2:Amazon Web Servicesが開発した推論用チップ
- Microsoft Maia:Microsoftが開発したAI加速チップ
これらのチップは、各社のデータセンターで実際に稼働しており、一定の成果を上げています。
「それなら、これらの企業はNvidia製品を買わなくなるのでは?」と思われるかもしれません。しかし実際には、これらの企業は自社チップを開発しながらも、依然としてNvidia製品を大量購入 しています。
その理由は、
- 汎用性の高さ:Nvidia GPUはあらゆる種類のAIモデルに対応できる
- 性能の高さ:特に新しい実験的なモデルでは、最高性能のNvidia GPUが必要
- エコシステムの広さ:CUDAベースのツールやライブラリが豊富
といった点にあります。
Nvidiaの戦略は、これらの自社チップを「脅威」と見なすのではなく、市場全体のパイが拡大している証拠 と捉え、共存を図るというものです。実際、AI市場全体が急拡大しているため、複数のプレイヤーが共存できる余地があるのです。
AI業界への影響と今後の展望
エネルギー効率が新たな競争軸に
Vera Rubinの登場は、AI業界における競争の焦点が変化していることを示しています。
これまでは、「より速く、より多く計算できること」が重視されてきました。しかし現在では、「同じ計算を、より少ない電力で実行できること」 が重要な差別化要因となっています。
その背景には、以下のような事情があります。
電力不足の深刻化
AIデータセンターの消費電力は急速に増加しており、一部の地域では電力供給が追いつかなくなっています。新しいデータセンターを建設しても、電力会社から十分な電力を確保できないというケースも出てきています。
電気代の高騰
AIサービスの運用コストの大部分は電気代です。エネルギー価格が上昇する中、同じサービスを提供するのに必要な電力を削減できれば、大きな競争優位性となります。
環境への配慮
企業の環境目標(カーボンニュートラルなど)を達成するためにも、エネルギー効率の高いシステムが求められています。
Vera Rubinの「ワットあたり性能10倍」という特性は、まさにこうした時代のニーズに応えるものなのです。
液冷システムの普及加速
Vera Rubinは、100%液体冷却システムを採用しています。これは、従来の空冷(ファンで空気を送って冷やす方式)では、220kWもの熱を処理しきれないためです。
液冷システムには以下のようなメリットがあります。
- 冷却効率が高い:液体は空気よりも熱を運ぶ能力が高い
- 騒音が少ない:大型ファンが不要
- スペース効率が良い:冷却のための空間を減らせる
ただし、液冷システムの導入には初期投資が必要です。配管工事、冷却液の循環装置、メンテナンス体制の整備などが求められます。
Vera Rubinの普及により、データセンター業界全体で液冷システムの導入が加速することが予想されます。これは、液冷システムを提供する企業(Delta Electronics、Vertivなど)にとっても大きなビジネスチャンスとなるでしょう。
年次イノベーションサイクルの定着
Nvidiaは、明確なロードマップを示しています。
- 2024年:Blackwell出荷開始
- 2026年後半:Vera Rubin出荷開始
- 2027年:Vera Rubin Ultra出荷予定(288 GPU/ラック)
- 2028年以降:次世代アーキテクチャ「Kyber」
このように、ほぼ毎年新世代の製品が登場するサイクルが確立されつつあります。
これは、スマートフォン業界で毎年新しいiPhoneが発表されるのと似たモデルです。顧客は「今年の最新モデル」を導入し、数年後にはさらに新しいモデルにアップグレードするというサイクルが生まれます。
Nvidiaとしては、この年次サイクルにより、継続的な収益の流れを確保できます。また、競合他社は「追いつこうとしている間に、次の世代が出てしまう」という状況に陥りやすくなります。
データセンターの設計思想の変化
従来のデータセンターは、多数の独立したサーバーを並べる「分散型」の設計が主流でした。しかし、Vera Rubinのようなラックスケールシステムの登場により、「統合型」 の設計へと移行しつつあります。
統合型の特徴は、
- ラック全体が1つのシステムとして動作:72個のGPUが密接に連携
- 超高速の内部通信:260TB/sのデータ転送速度
- 集中管理:電源、冷却、ネットワークが一元管理される
といった点にあります。
この変化は、データセンターの設計、建設、運用のすべてに影響を与えます。建物の設計段階から、220kWの電力供給と液冷システムを考慮する必要がありますし、床の耐荷重も1ラック2トンに耐えられるよう設計しなければなりません。
次世代Vera Rubin Ultraへの展望
Nvidiaはすでに、Vera Rubinのさらに次の世代となる 「Vera Rubin Ultra」 を2027年に出荷する計画を発表しています。
Vera Rubin Ultraの主な特徴は、
- 288 GPU/ラック:Vera Rubinの4倍のGPU数
- Kyberアーキテクチャ:新しい接続方式により、ケーブル数を大幅削減
- 重量増加はわずか50%:288個のGPUを搭載しながら、軽量化設計
というものです。
Nvidia幹部は次のように述べています。
「接続ポイントを減らし、故障点を減らし、統合度を上げる。これによりシステムは高速になるだけでなく、総所有コストも下がる」
ケーブルや接続部が少なくなれば、それだけ故障のリスクも減ります。また、より高い統合度により、さらなる性能向上とコスト削減が期待できるのです。
市場全体への波及効果
Vera Rubinの登場は、AI業界全体に様々な影響を与えます。
AIサービスの価格低下
トークン生成コストが10分の1になれば、AIサービス事業者は価格を下げる余地が生まれます。これにより、より多くの人々がAIサービスを利用できるようになり、市場全体が拡大します。
新しいAIアプリケーションの登場
これまでコストの問題で実現できなかったAIアプリケーションが、現実的なものになります。例えば、リアルタイムの動画生成、個人ごとにカスタマイズされた教育プログラム、高度な医療診断支援などです。
半導体サプライチェーンの再編
HBM4メモリの需要急増により、メモリメーカーは設備投資を加速させます。また、液冷システム、高速ネットワーク機器など、周辺産業も成長します。
データセンター建設ブーム
Vera Rubinのような高性能システムを収容できる、次世代データセンターの建設が世界中で進みます。これは建設業界、電力業界にも大きな影響を与えます。
まとめ:AI時代の基盤を支える技術革新
ここまで、Nvidia Vera Rubinについて詳しく見てきました。最後に、重要なポイントをまとめておきましょう。
技術的な革新
Vera Rubinは、6つの新設計チップ、130万個の部品、72個のGPUを統合した、次世代AIインフラシステムです。推論トークンコストを10分の1に削減し、ワットあたり性能を10倍向上させるという、驚異的な効率性を実現しています。
エネルギー効率の重要性
AI業界において、単なる計算速度だけでなく、「同じ仕事を、より少ない電力で実行できること」 が重要な競争軸となっています。電力不足と電気代高騰が深刻化する中、Vera Rubinのエネルギー効率は大きなアドバンテージです。
グローバルなサプライチェーン
80社以上のサプライヤー、20ヶ国以上の製造拠点、約350工場から部品が集められます。この複雑さは、Nvidiaの強みであると同時に、供給リスクでもあります。HBM4メモリの供給不足は、今後の出荷ペースに影響する可能性があります。
競合との差別化
AMD Heliosなどの競合製品も登場しますが、NvidiaのCUDAエコシステム、ラックスケールシステムの経験値、年次イノベーションサイクルは、強固な競争優位性を生み出しています。
業界全体への影響
Vera Rubinの普及により、AIサービスの価格低下、新しいアプリケーションの登場、液冷システムの普及、次世代データセンターの建設など、AI業界全体に大きな変化が訪れることが予想されます。
次世代への展望
2027年にはVera Rubin Ultra(288 GPU/ラック)が登場予定であり、Nvidiaの技術革新は今後も続いていきます。年次アップグレードサイクルの定着により、継続的な進化が期待できます。
私たちが日常的に使うAIサービスの裏側には、こうした最先端の技術が存在しています。Vera Rubinのような次世代システムにより、AIはさらに身近で便利なものになっていくでしょう。
技術の進化は止まりません。今後も、Nvidiaをはじめとする企業がどのような革新を生み出していくのか、注目していきたいですね。





最新のコメント